前言
最近在哔哩哔哩做了一期直播技术分享,算是人生中第一次吧🙂内容是基于 Kubernetes 和 Skywalking 的 Spring 微服务监控实践,实现 Spring 云原生可观测性。自己排练的时候,准备了一个多小时的内容,结果直播时太紧张,半个多小时就讲完了😂
本来打算用 PPT 整理一些概念和注意点来讲,然后结合项目讲解项目怎么配置、怎么部署,以及请求进来了,怎么通过 Skywalking“观测”请求走过的调用栈,以及查看日志等。由于时间问题,部署这一块就省略掉了,只展示了最终的效果,毕竟部署特别费时间。后面也打算从 0 开始,搭建 K8S,然后部署 nacos、redis、数据库之类的,再把项目和 skywalking 给部署上去。直播录屏正好可以拿来做项目的视频部署教程,也锻炼锻炼自己临场实践能力,以及出问题了怎么查资料去解决。
开播前后有很多朋友的鼓励和支持,这里谢谢大家!本文的内容算是与视频内容的互补。
让我们开始
为什么需要 Skywalking?
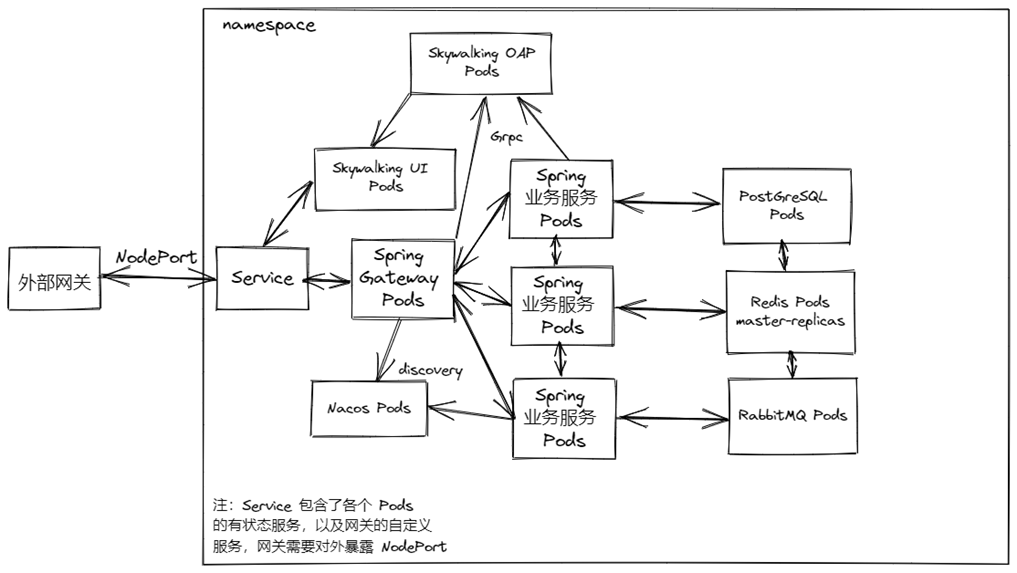
在 Spring 微服务场景中开发过的小伙伴应该都了解,我们在排查问题的过程中,往往会因为调用栈太长、跨过的服务太多、请求量太大、无法准确追踪异步线程等,浪费大量的时间。这种情况并不像单元测试对功能性方法测试一样,很方便的就能看到报错信息以及 Debug,我们需要有一种方式,帮我们追踪每一个”请求“线程,来实现”观测“。
拿图中的架构来举例子,请求打到外部网关入口,然后被转发到 Spring-Gateway 所在的 Service 的 NodePort,对应的流量会负载均衡到每一个这个 Service 内的 Pod。然后 Spring Gateway 会根据路由,将流量转发到对应的业务服务。业务服务可能会操作数据库、redis 以及消息队列之类的中间件,最终处理完之后,将响应回对应的请求。而这个过程产生的日志和监控数据,将会被上报给 Skywalking OAP,我们访问 Skywalking UI 的 Service 就能看到界面了,通过各个图表获取我们需要的信息。
程序在出现异常时,会将 traceId 一并响应给请求方,这样就可以通过 traceId 去 Skywalking 查询相应的数据了。在上线前,它有一个典型的案例场景:测试自己复现了 Bug 之后,拿到 traceId 给开发,开发去 UI 查看日志和数据。极大地降低了测试和开发人员间的友好互动频率、维护了团队的良好氛围形象、提升了 bug 响应修复的速度,同时避免了在测试电脑上有 bug 但在开发电脑上世界和平的现象(笑死
注意:这里每个负载间都是通过 Service 的虚拟 IP 来通信的,不能够使用 Pod IP,因为重新部署后 IP 会发生变化,同时也将无法做到负载均衡了。
Skywalking 是什么?
SkyWalking 是一个开源可观测平台,用于收集、分析、聚合和可视化来自服务和云原生基础设施的数据。SkyWalking 提供了一种简单的方法来保持分布式系统的清晰视图,甚至跨云。它是一种现代 APM,专为云原生、基于容器的分布式系统而设计。
SkyWalking 为服务(Service)、服务实例(Service Instance)、端点(Endpoint)、进程(Process)提供可观察性能力。
服务可以映射成我们的 Spring 的每一个服务,在 Kubernetes 中也就是 Service,而服务实例对应着 Service 内的 Pod(举个例子:咱们的 Spring Gateway 网关”服务“,可以启动多个实例对吧?)。而在开发中我们最常关注的是端点,端点用于传入请求的服务中的路径,例如 HTTP URI 路径或 gRPC 服务类 + 方法签名。
举个例子,前端请求后端的登录接口,
http://127.0.0.1:8000/pisces-admin/user/login,就可以是一个 endpoint,这个 endpoint 的内容是POST:/user/login。
SkyWalking 在逻辑上分为四个部分:Probes、Platform backend、Storage 和 UI。作为开发,我们最需要关注 的是 probes 和 ui,probes 可以理解为程序中的“探针”,而 ui 是我们“观测”数据指标的界面。
如何收集 Java 程序的数据?
介绍完 Skywalking 的一些概念之后,我们最关心的肯定就是如何从 Java 程序中收集数据。刚才我们说到了”探针“,我们就是要靠它来实现。
在 SkyWalking 中,探针是指集成到目标系统中的代理或 SDK 库,负责收集遥测数据,包括跟踪和指标。
SkyWalking Probes 可以分为四种不同的类别:
- Language based native agent,也就是基于语言的原生代理
- Service Mesh probes
- 3rd-party instrument library
- eBPF agent
显而易见,我们要用的就是针对于 Java 的基于语言的原生代理,也就是 Skywalking Java Agent,它为 Java 项目提供本机跟踪/指标/日志记录/事件功能。
如何使用
在项目中使用 skywalking agent
本文以 logback 日志实现为例,首先我们要将下面的包引入进我们的项目:
| |
注意:只要你的微服务项目配置了全局的 spring-cloud 版本,那么这里的 sleuth 就不需要单独指定版本,它会默认继承你当前
spring-cloud-dependencies指定的版本。
- 在
logback-spring.xml中添加 gRPC reporter.
| |
注意,name 参数可以自定义,但是记得加上 appender:
| |
- 下面这行插件的配置,如果不添加的话,会使用默认值:
log.max_message_size=${SW_GRPC_LOG_MAX_MESSAGE_SIZE:10485760}
到这里,我们已经配置好基本的内容,这下你的服务已经可以上报数据了。
Skywalking 服务配置
程序中配置好了,那么我们把数据上报到哪里,以及如何查看呢?这里以开发环境为例子,毕竟如果在本地开发的话,还是需要调试的。
- 安装 skywalking
我们先去官网下载 Skywalking APM,下载完之后解压,本地我们不做特殊配置,直接双击 apache-skywalking-apm-bin\bin\startup.bat 就可以启动了。启动之后,访问 http://localhost:8080,就可以看到页面啦!
启动完之后进去是没有数据的,等程序上报数据就好了。
- 安装 skywalking java agent
我们需要在程序启动时,让 agent 以插件的形式加载进来,当然也需要下载这些包了。去官网下载 Skywalking Java Agent,然后解压之后得到 skywalking-agent 文件夹。点进去之后我们可以看到一个 jar 包 skywalking-agent.jar,记住这个包在你硬盘上的绝对路径。
由于 Spring Gateway 是基于 WebFlux 的,所以我们要添加 2 个插件进来。进入 skywalking-agent\optional-plugins 文件夹,找到如下 2 个 jar 包:
apm-spring-cloud-gateway-3.x-plugin-8.13.0.jar
apm-spring-webflux-5.x-plugin-8.13.0.jar
然后复制到 skywalking-agent\plugins 文件夹下就行了。
注意,具体的版本,取决于你当前所用的版本!
idea 配置
接下来我们去 idea 中配置,以便让 idea 中的 Java 服务启动时能顺利加载插件。
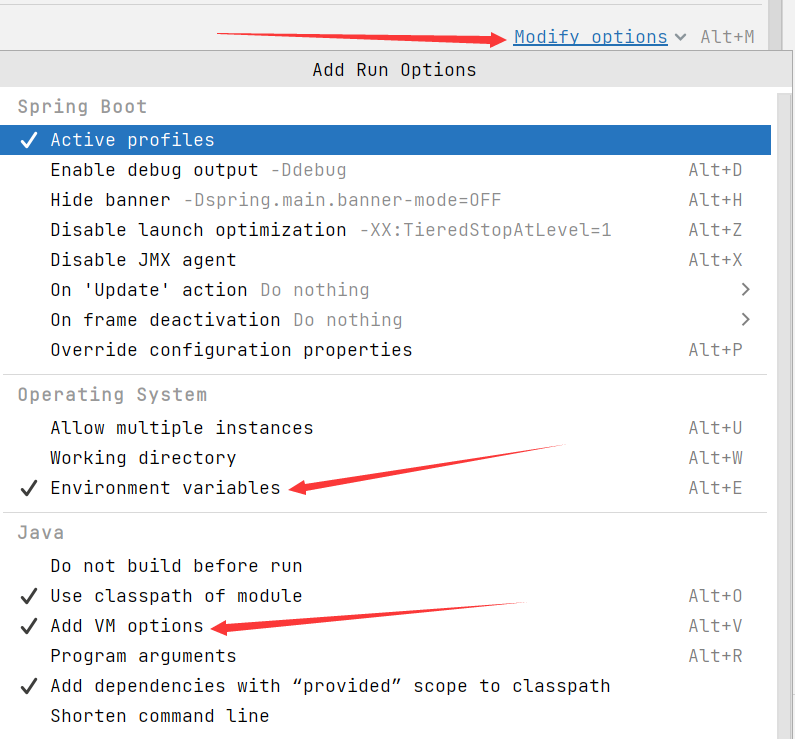
我们先打开 Run/Debug Configurations,然后找到我们对应的服务(没有的就添加),选择 Modify options,勾选 Environment variables 和 Add VM options 选项。
然后添加对应的启动参数:
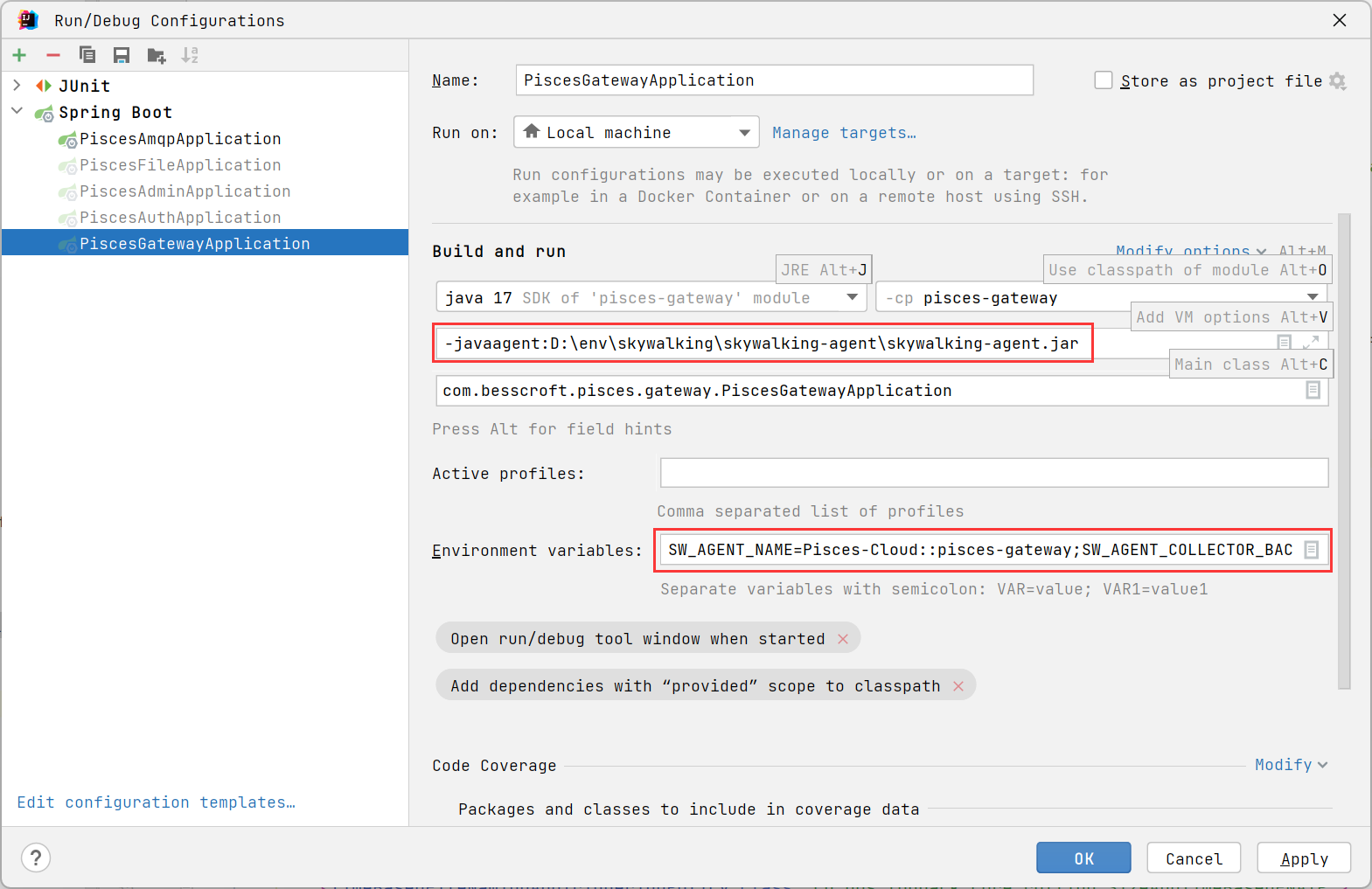
第一个红框框的内容,是 JVM Options 参数:
-javaagent:D:\env\skywalking\skywalking-agent\skywalking-agent.jar
在 -javaagent: 后面的是你开发环境的 skywalking-agent.jar 包的绝对路径位置。
第二个红框框,是配置 SkyWalking Agent 的环境变量:
SW_AGENT_NAME=pisces-gateway;SW_AGENT_COLLECTOR_BACKEND_SERVICES=127.0.0.1:11800
SW_AGENT_NAME 的值填写你要指定的 Service Names,如果你需要同时配置 Service Groups,你可以这样写:
SW_AGENT_NAME=Pisces-Cloud::pisces-gateway;
:: 符号前面的就是 Service Groups,后面的就是 Service Names。
SW_AGENT_COLLECTOR_BACKEND_SERVICES 的值填写你的 SkyWalking OAP 的 Agent Backend Service 的地址。
图表信息
直播时基本上都介绍过了,这里挑几个典型大致讲讲吧。
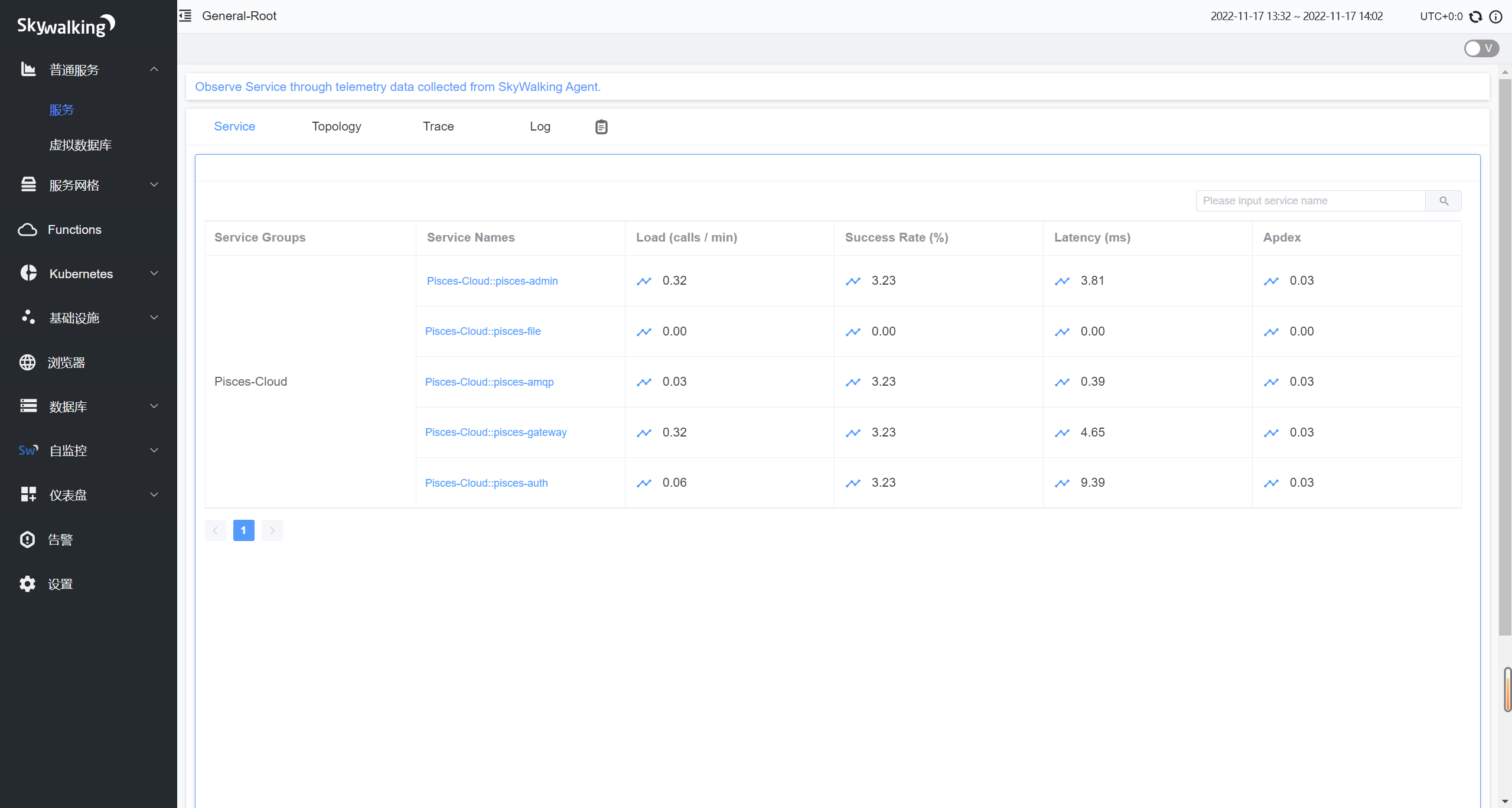
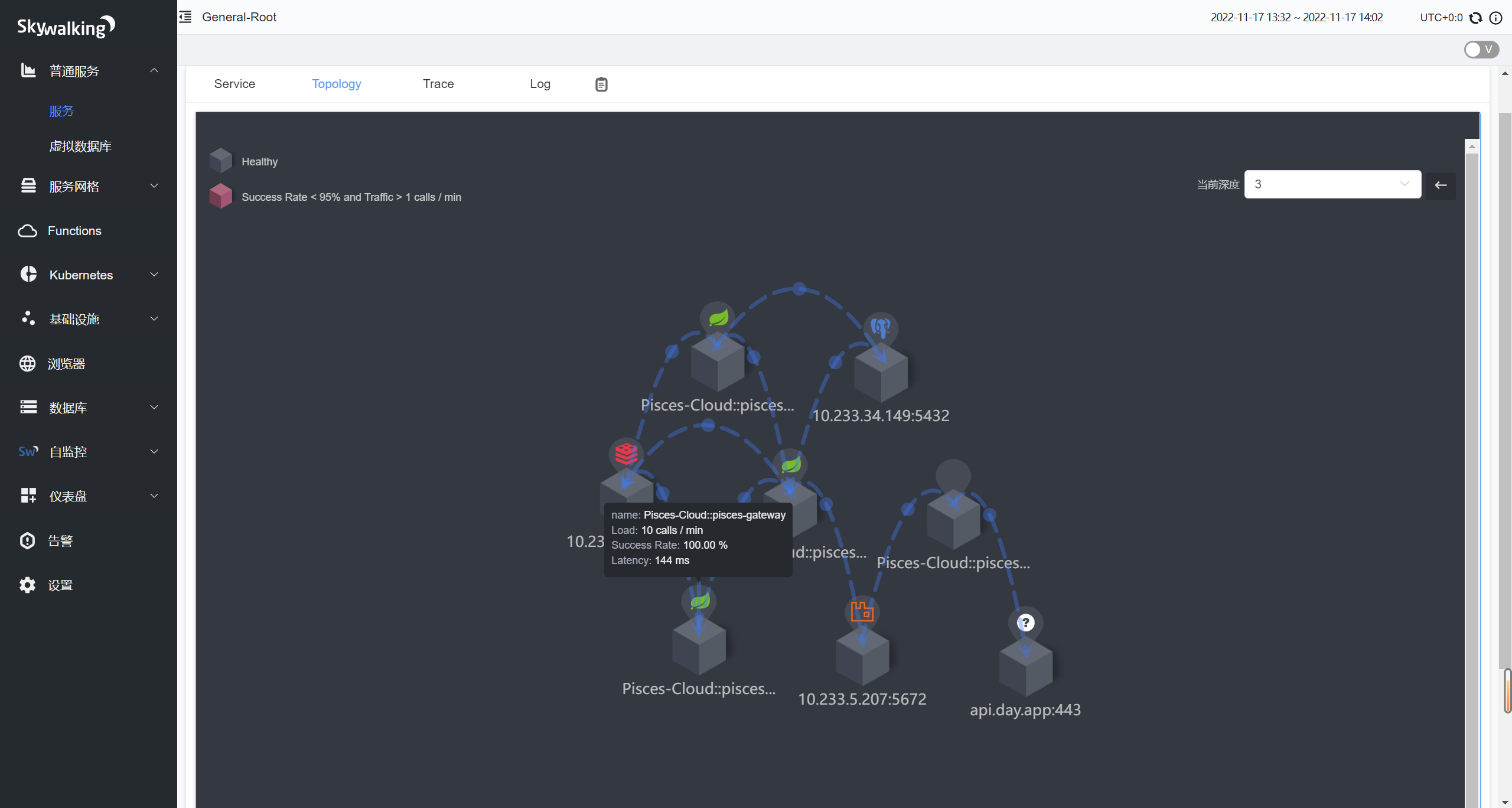
图中我们看到的是服务概览,以及整个服务链路的拓扑图。当然,关于链路追踪重要的部分,还得是 Trace 和 Log,下面我以 POST:/user/login 这个登录的端点来举例子。
调用链路信息
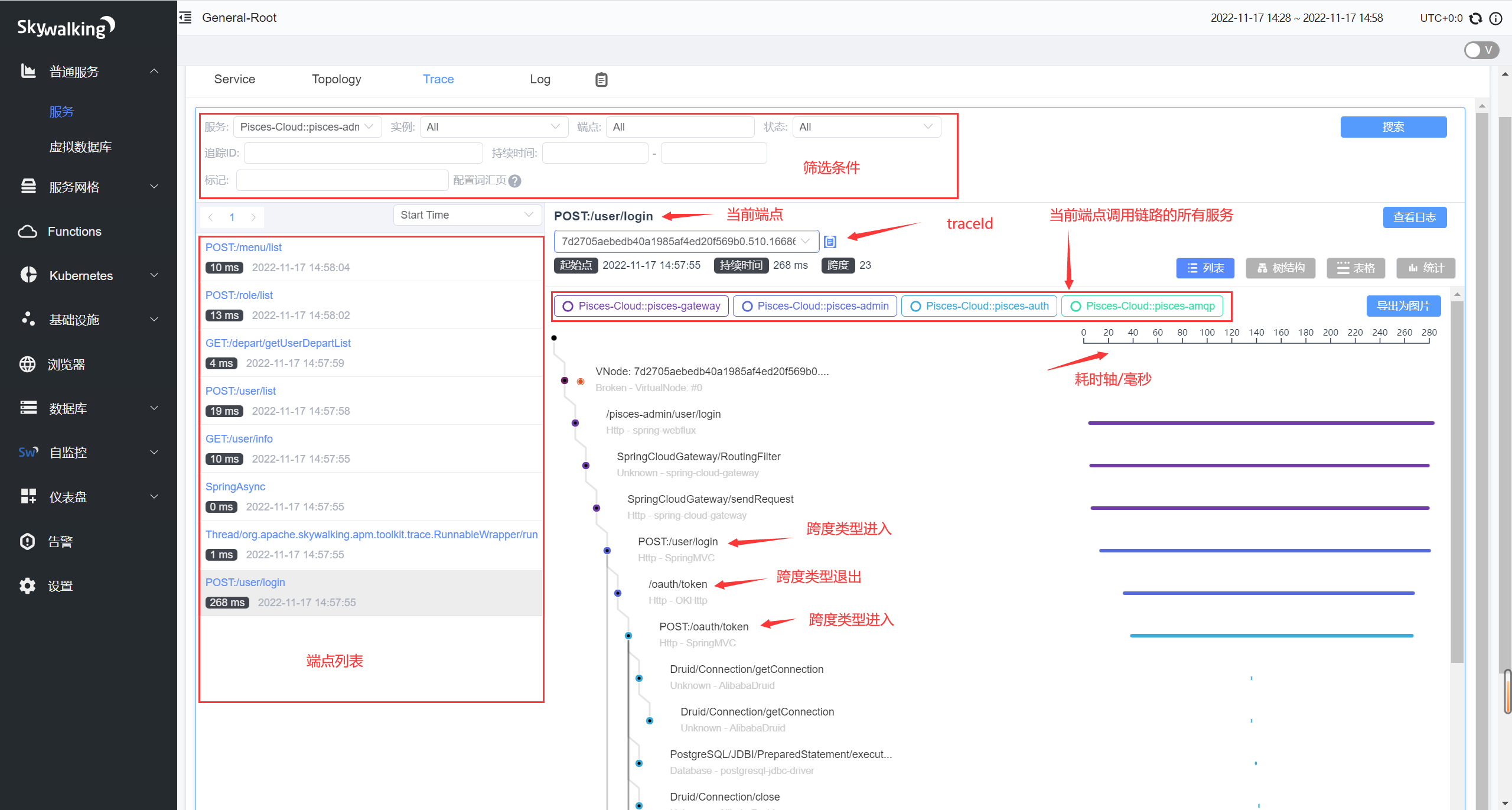
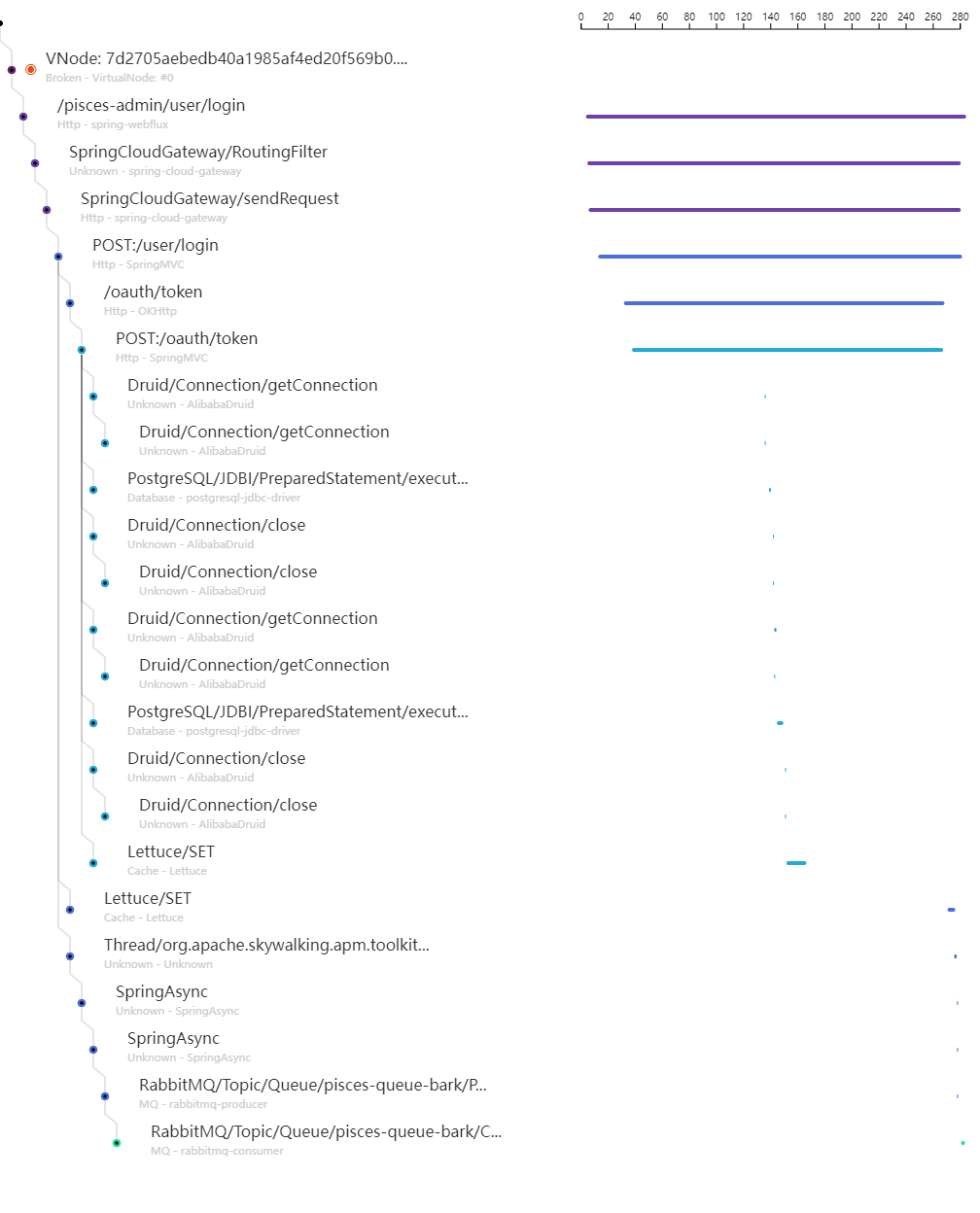
我们可以看到每一个上报过的端点,以及端点对应的信息。图中端点的请求走过的每一个不同的服务,都是用了不同的颜色区分开了。而竖着的直线,就是对应着当前的服务,中间的每一个跨度都能点开查看日志,包括执行的 SQL 语句,然后只要输出了日志信息,都可以关联到对应的 LOG,是不是特别方便?下面放一张全貌图。
服务业务数据图表
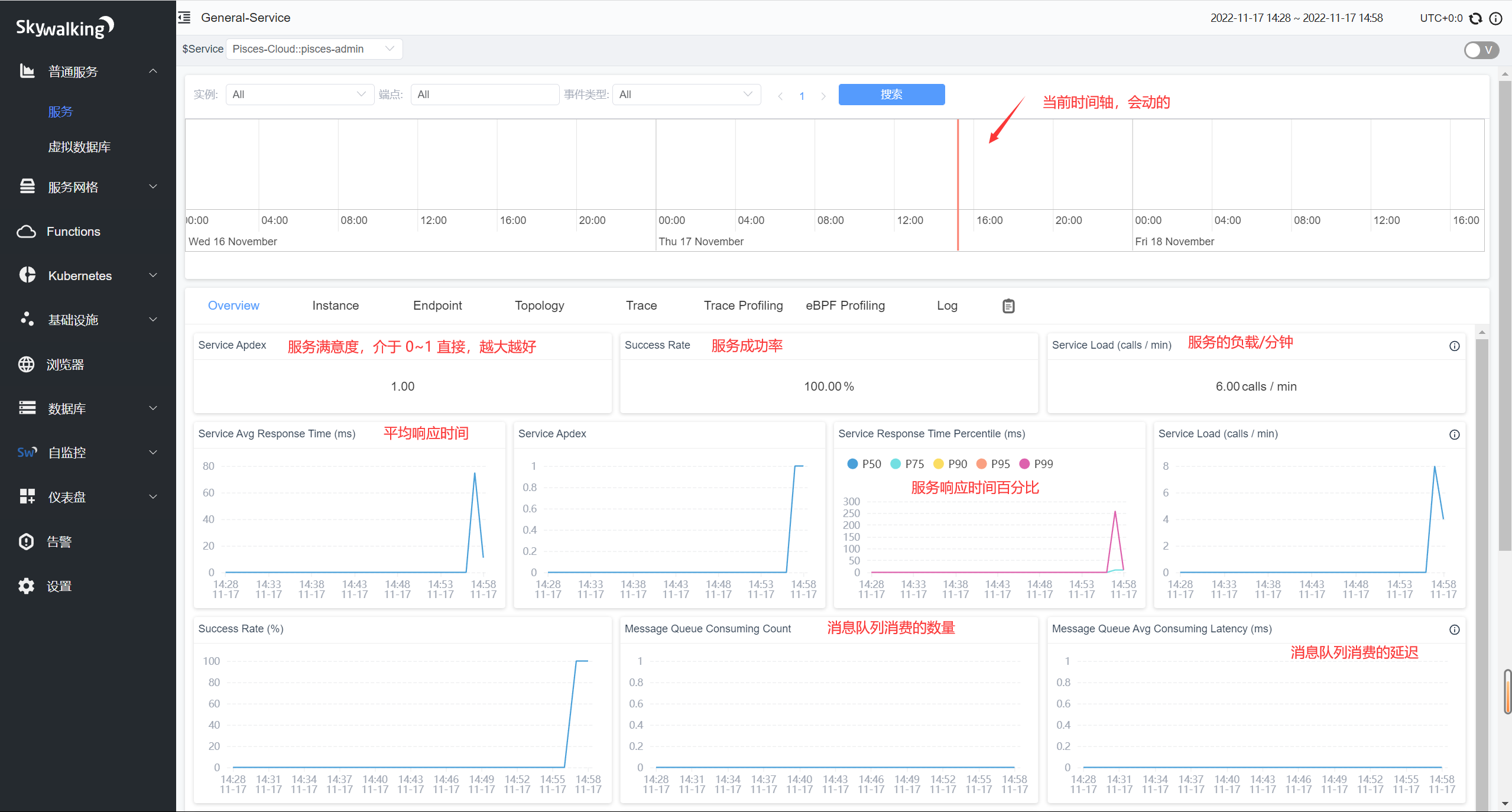
图中的注释已经说的很详细了,有一点需要注意的是,消息队列相关的那 2 个图表,需要你当前服务具有”消息消费者“的时候,才会显示数据的,毕竟是展示 Consuming 数据嘛。
JVM 数据图表
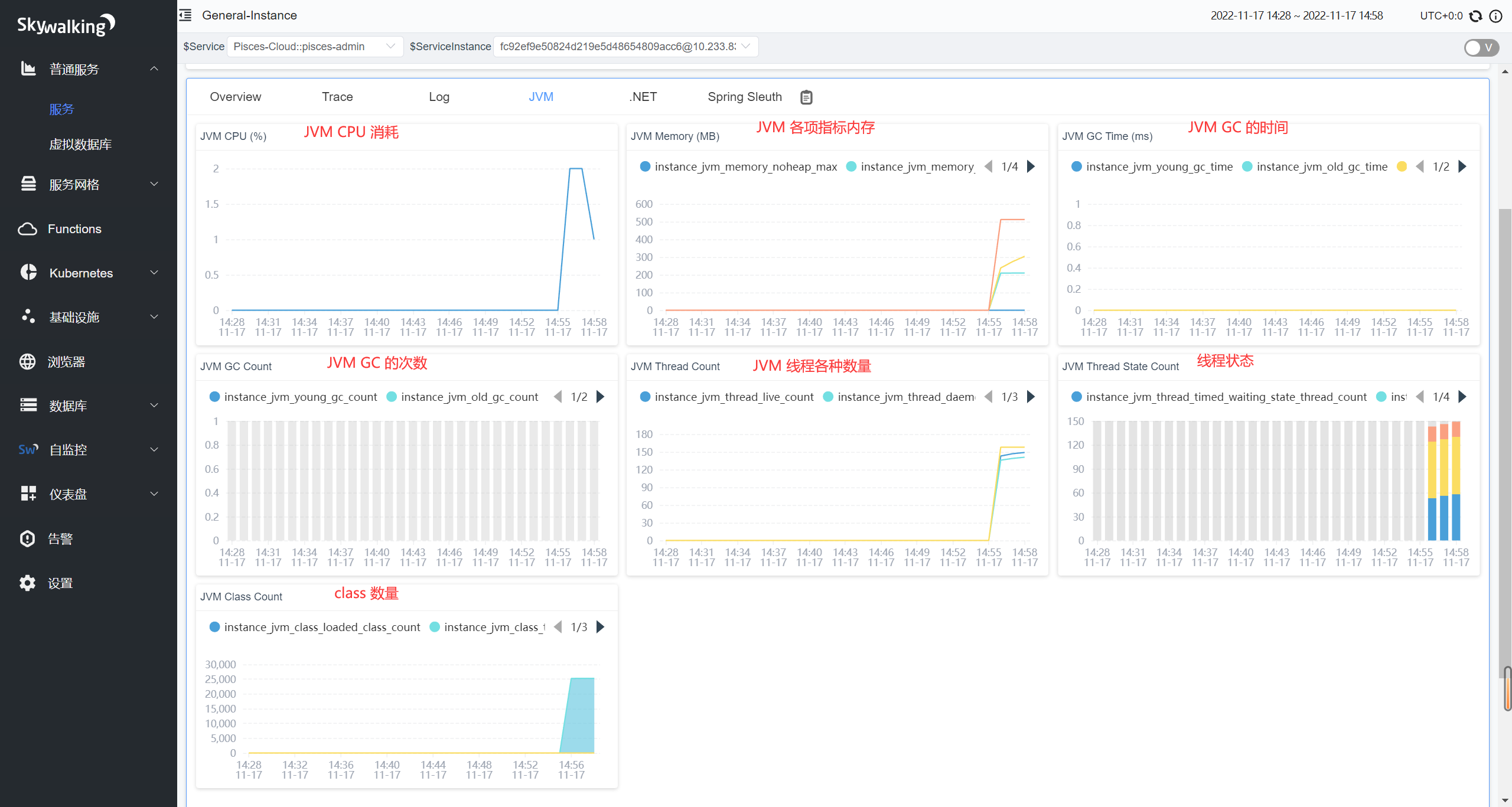
每一个实例进去,都能够看到对应的 JVM 的信息,毕竟有时候需要诊断 JVM 数据来定位问题嘛。我们可以看到有内存/CPU占用情况,新生代、老年代的 gc 时间和次数,各种状态的线程(守护线程、阻塞线程、可运行线程、等待线程)次数啦等等。
毕竟对于初学者来说,学习使用各种工具去查看这些指标,是需要一定的精力的。尤其是碰到线上不给任何权限的那种,这时候程序能够主动上报数据,我们就能直观的看到了。
注意,线上环境的任何观测/上报数据的接口,都不建议对外公开访问,做好白名单/黑名单机制拦住它。
开发中的注意点
跨线程追踪
程序中教程会碰到,需要用异步线程处理的情况,那么这种时候如果需要对异步线程进行追踪的话,可以采用跨线程追踪方案。
- 首先我们先引入包:
| |
- 拿下面这个场景来说,我需要发送一条消息:
| |
这种写法是无法追踪到的,在引入包之后,我们可以这么写:
| |
值得注意的是,CompletableFuture.runAsync() 是没有返回值的,所以用的是 RunnableWrapper.of(),如果我们用的是 CompletableFuture.supplyAsync() 的话,就需要换成支持返回值的 SupplierWrapper.of() 方法。
全局异常处理
全局异常处理这基本上业务开发都会用到,但是我们抛给前端的信息中,需要带上 traceId,这样不管是用户还是测试,都可以根据报错信息中的 traceId 反馈问题,排查也就减轻了一些负担。
- 首先引入相关的包:
| |
- 通过 Skywalking 手动 API,我们可以获取到 traceId:
| |
- 然后加到异常处理中响应给前端:
| |
- 响应的异常信息如下:
| |
traceId 生成规则
生成的 traceId 一大串,怎么读懂它?(虽然只是个符号而已,但是我们也可以了解下)
先看源码:
| |
我们知道,traceId 是由 2 个点分隔开的一串长字符串。第一个点前面是生成的 UUID,并替换掉了 - 符号;中间的三个数字,是当前线程的线程 ID;最后的内容是根据时间戳 * 10000 + 当前线程中的 seq 生成的。UUID 生成后就不会变了,线程 ID 也是一样。
注意,这里的线程 ID,并不是请求线程的线程 ID,说它是当前实例的生成器的线程 ID 更合适。而且 UUID 和线程 ID,每一个不同的实例生成的也是不同的,只是每一个实例下相同。这点其实也很好验证,每个 Service 启动多个实例,然后来一波多线程压测就显而易见了。
最后
这是第一次做直播技术分享,也非常感谢大家的支持!虽然第一次看的人不多,但是也留下了录屏,而且依旧可以写博客发出来,算是一次不错的经历,以后也打算继续做直播技术了,偶尔直播技术分享,同时也欢迎大家多多跟我交流技术呀!