前言
最近在设计开发嗯学英语项目,今天想简单讲点儿故事,一个关于英语学习软件背后复杂的技术设计思考,以及我打算如何实践,让它以何种方式运作。
摸索
英语类学习软件我用过不少,使用时间最长的,那自然是多邻国了。你看你学了这么久英语了哈,如果现在要你来做一款英语学习软件,你要如何设计(doge
功能梳理
一句话总结,就是查询单词信息,记录用户学习状态。看着很简单对吧?相信我,如果有人这么跟你提需求让你实现,还跟你说很简单,你一定想拍死他。
开个玩笑哈哈,现在我们来详细分析一下业务:
首先我们得让用户选择学习哪一个词库的,我们就拿《考研英语词汇》来说吧,一共 4533 个词。
在用户选择词库后,我们可以生成一条该用户对这个词库的学习汇总数据,也就是哪些单词用户“学习”了,总共学了多少个等等。
然后用户在软件上获取单词进行学习,在学习完成后,数据将会进行入库操作。这里的入库操作就涉及到比较多的点了,比如咱们要记录单词用户是否“学过”,也就是说不管题目是答对还是答错,都算学过。然后就是单词的进度统计,总共多少个,学了多少个了。以及把用户做错的也记录下来,形成错题本。
这里有必要给大家解释一下,为什么会需要记录学习数据。相信很多小伙伴应该都听过艾宾浩斯遗忘曲线,而我们让用户学习,也不可能一个请求就给一个单词,那样不仅效率低,而且服务器也会绷不住。正确的做法是,生成一个 List,相信用 Excel 背过单词的小伙伴是会深有体会的。因为某个单词用户学习了,入库肯定是会做时间记录的,结合用户的行为,以及错题本,就可以根据一些“记忆算法”来生成 List。由于这个功能只是整块业务的一小部分,这里就不作展开了。
通过这个开发中的初版 UI 草图,我们可以理解一下,以上的功能映射到用户端的大致模样。
数据库表设计
梳理完业务功能后,首先我们要设计数据库表。在消耗了几杯咖啡,挠掉了一些头发后,我设计了如下的数据库表结构(当然,开发迭代的过程中也是会做出调整的):
- 用户活动词库表,用来记录用户当前正在学习的词库、学过的词库,以及统计已学单词数量。
| |
- 用户学习行为表,用来记录用户“学习”过的单词,以及学习时间等。
| |
- 用户错题本,用来记录用户学习错误的单词,以及次数。
| |
流程
现在咱们来看看,整套流程是怎么走的:
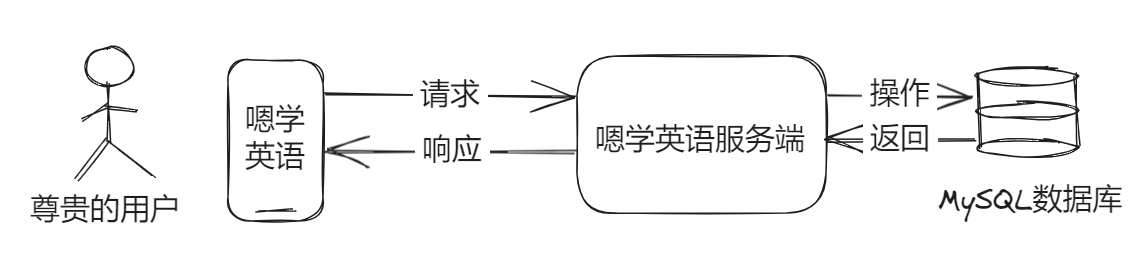
就是一个很典型的 Spring Boot 单体架构服务,对吧?用户端操作,请求到后端服务,然后后端服务操作数据库,并返回。有一点需要注意,服务本身是“无状态”的,所有的状态咱们都在数据库和分布式缓存中进行维护,否则的话就没法舒适地扩展了。
这里的“无状态”指的是,服务端的无状态认证(Authentication),属于“会话状态”的讨论范畴,不要弄混淆了。因为我把用户的状态写入了分布式内存中,而不是当前服务的缓存中,所以不会因为扩展了多个实例而导致状态隔离。
那么到这里为止,咱们就把核心业务给设计完了。
改进
服务器瓶颈改进
由于嗯学英语并不是离线客户端模式,所以还是很依赖于云服务的。我们不可能说,开发一个软件,就只能让一两个人用,人一多就崩溃对吧?那么我们这里做个假设,我们的用户跟多邻国一样多(可以压测模拟),这时候应该如何调整架构来支持呢?
首先说一下目前嗯学英语的整个技术栈和架构,然后我们以此为基础代入思考。
前端:Nuxt 3、Vue 3、TypeScript、Naive UI、TailwindCSS
后端:Spring Boot 3、OpenJDK 17
数据库及中间件:MySQL、MongoDB、Redis
CI/CD:GitHub Actions、Kubernetes
我的云服务资源能拿来演示的没那么多,我这里就单个服务分配 512 MB 内存来进行演示
在我们开始进行压测后,不难发现单台服务根本顶不住多少“用户”同时使用。好在我们一开始设计时,就考虑到了扩展的问题。我把服务部署在了 K8S 里面,而且嗯学英语服务是无状态的,那么基于 Service(服务)和有状态副本集(StatefulSet)来完成有序的、优雅的部署和扩缩,只需要增加容器组副本数量就行了。
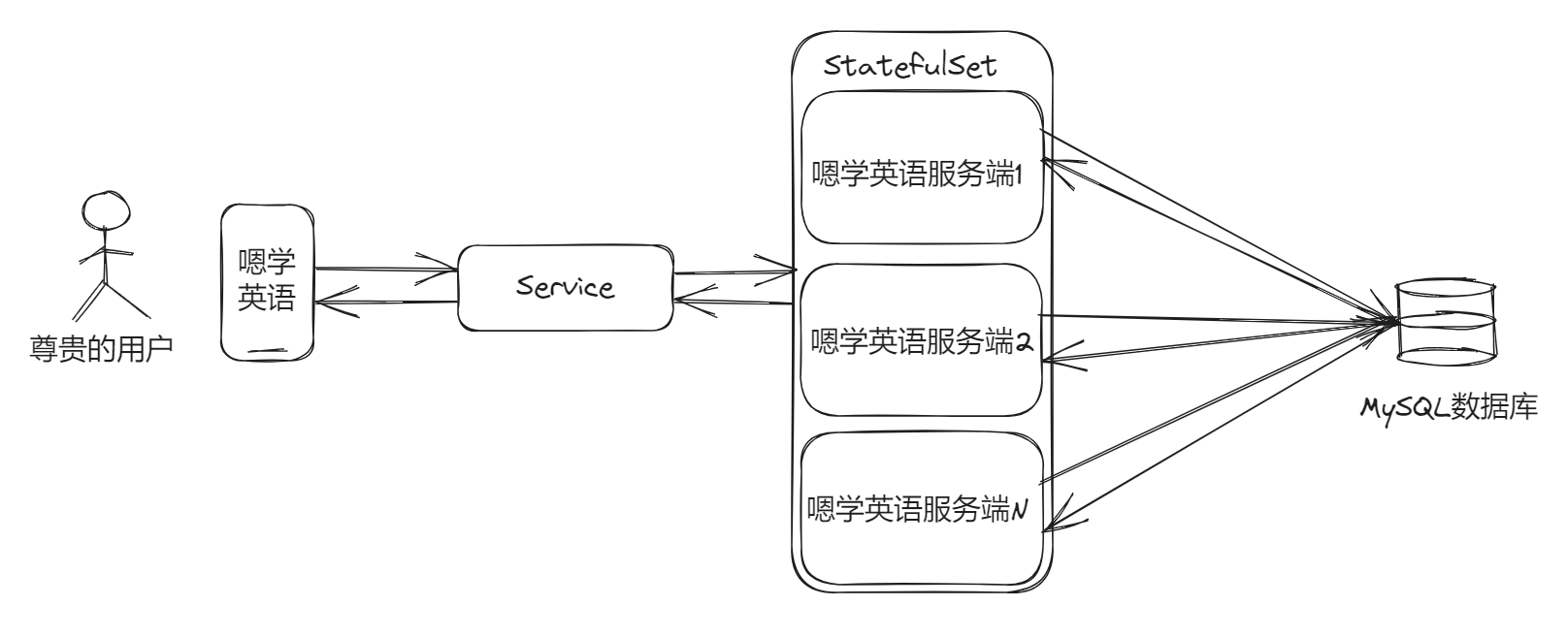
这样一来,客户端不需要关心它们调用了哪个后端副本,通过快速扩容,我们也能容纳更多的请求,现在能够支撑上 w 用户同时使用了。
数据库瓶颈改进
在压测了一段时间后,我们可以发现瓶颈来到了数据库这边。数据库 CPU 占用高、连接数过高(too many connections)、wait timeout 等问题全来了。
我们知道,MySQL 的最大连接数是有一个上限的,但是呢,我们不可能直接设置为上限的那个数,需要根据服务器的 CPU、内存大小等来设置一个相对合理的值。我一般默认 210,最大 1000(别问我能不能再大点儿,得加钱!!!)。
数据库咱们没法像服务那样直接更改部署副本大小就行,要考虑的因素特别的多,毕竟数据才是值钱的东西呢!这里场景的方案就是上集群,一个主实例(读写,也可以多个主实列)和多个辅助实例(只读),这里贴一张 MySQL 文档中的图片:
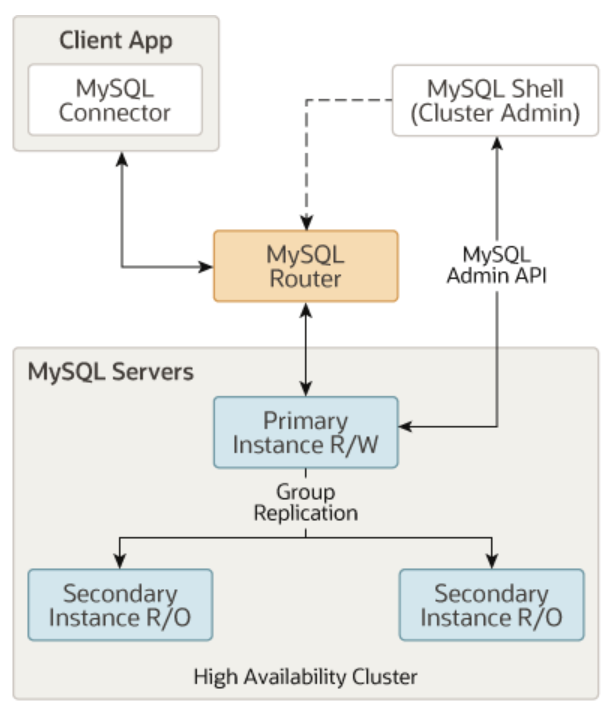
反映到嗯学英语架构中来,应该是这样的:
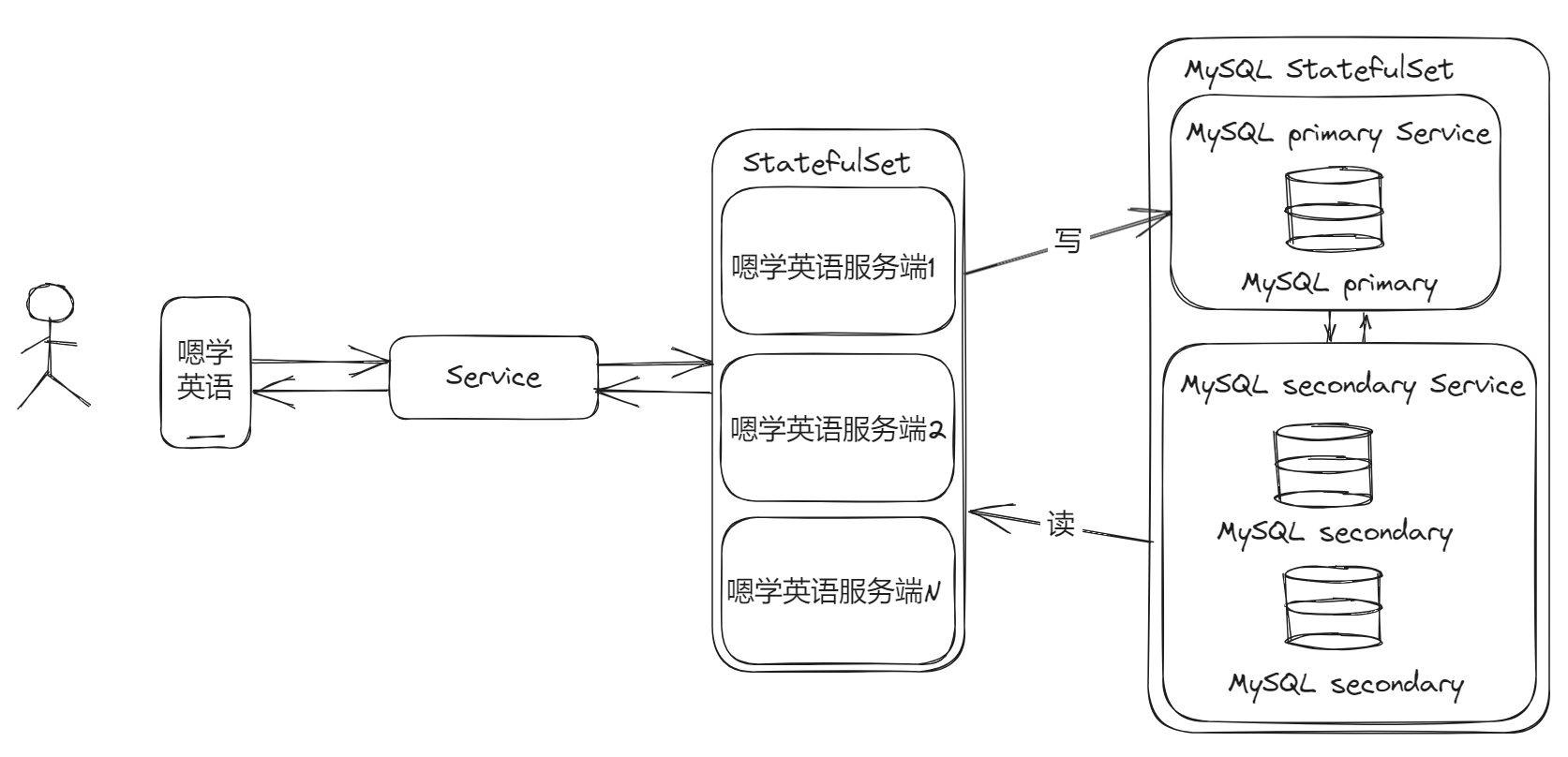
初次在 K8S 部署学习 MySQL 集群的话,可以试试 Bitnami 的 MySQL Chart,基于这个入手会更好!
在实际开发中不可能一句上集群就能上的,说起来轻松的事儿,只适合面试吹牛。作为一名开发,还是得先从代码设计层面去解决问题。仔细回想一下,单词数据、错题本之类的数据,是不是都是读多写少的场景?那么我们就没有必要每次都去数据库读了,而是读取之后做缓存,在每次更新数据之后,再更新缓存,这样能降低一些数据库的压力。
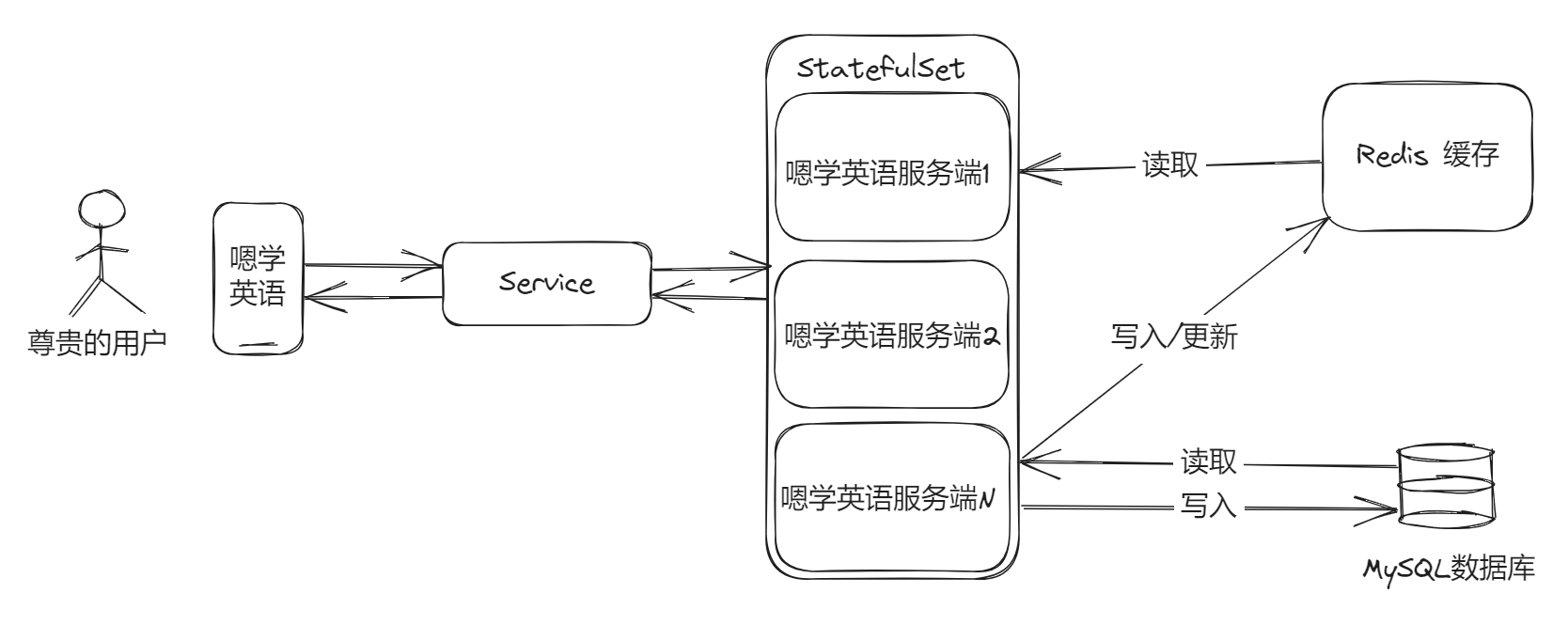
连接数解决
这个一般微服务场景下会比较好做一些,要么基于 K8S 的微服务,要么 Spring Cloud,由于我们的嗯学英语前期采用的是 Spring Boot 单体项目,如果用这个方案的话,是需要对架构进行调整的。但是我觉得多邻国肯定不是单体服务,所以还是像拿出来讲讲。
咱们前面不是扩容了很多服务嘛,那么假设每一个服务,我们都分配了最大 50 个连接数的数据库连接池。理论上来说,服务副本数量越多,会占用的数据库连接数也就会变多。
有一句很有名的话,“计算机科学中的所有问题都可以通过另一个间接层次来解决”,据说是大卫·惠勒说的。把这个思路引进来,我们可以发现增加服务副本,是为了缓解核心业务里面对于数据库的“相同”操作,那么我们可不可以把这些操作抽象出来,封装成“间接层”呢?那当然是没问题的了!
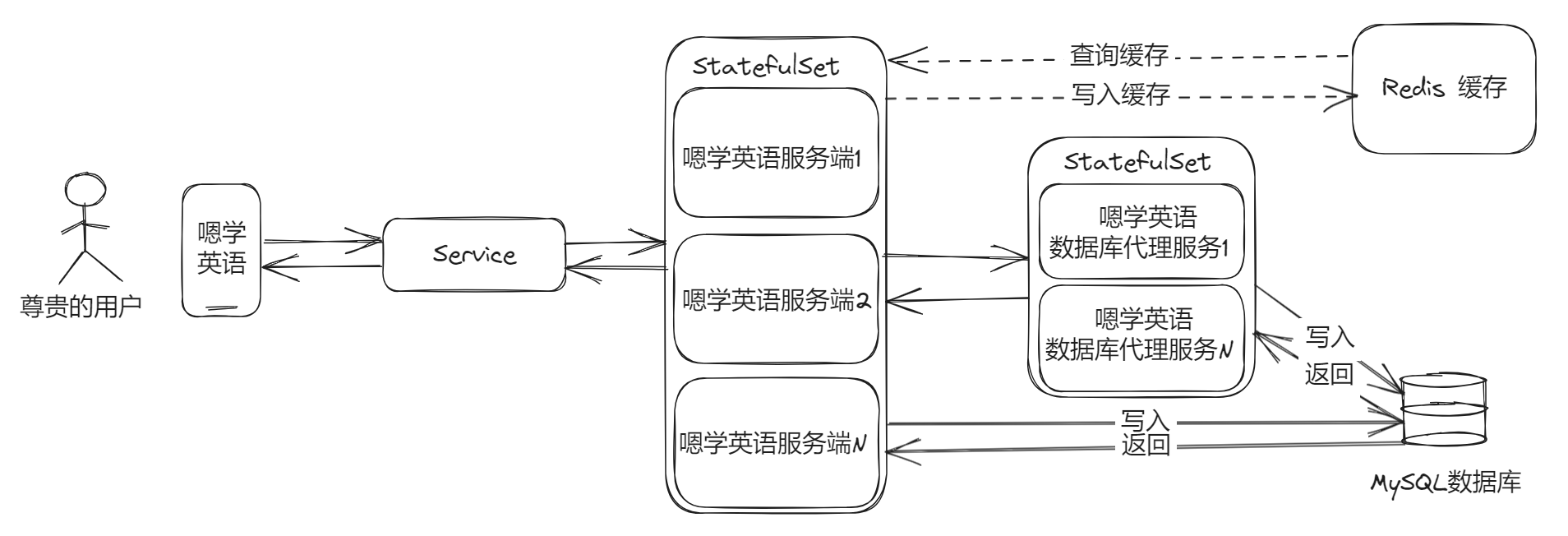
在加入了代理服务之后,就能极大地缓解这个问题了。注意哈这一套在微服务里面要好做一些,单体服务弄这个的话,维护起来相对麻烦。
异步
在解决了上述问题之后,假设某一天嗯学英语突然爆火了,10w+ 的用户全部跑来试用(咱们增加压测线程来模拟),咱们的服务器还是崩啦!
虽说大部分场景下,每个用户对数据库中同一条数据的操作相对来说并不多,但是也没法保证出现死锁或者锁竞争的问题。我们的业务,也是在每次用户操作发送请求后,直接入库,等待操作完了之后,才返回的。虽然是第一次做,但是我们可以分析下多邻国看看有没有什么思路。
多邻国在每次完成一个单元的测试后,都会有一个“短暂”的结算动画,甚至有时候去个人档案页面,看到的数据统计和成就,并不是刷新好了的,可能要等个 1~3 秒左右。这类学习类 App 对于用户来说,是具有很高的容忍度的,配合上动画,反而体验看上去也很不错。那么在这中间缓冲的一点时间,就可以让后端服务“慢慢地”去入库就行了,用户感知也就没那么明显了,只需要最大程度的保证数据能保存下来就行。
这里可以在代理服务里面用线程池去处理,或者是用消息队列,然后让代理服务去消费它。在嗯学英语的架构中,我会选择使用 RabbitMQ(消息队列中这个我用的最熟,选其它的也没问题),原因也很简单:我需要能优雅的管理代理服务的集群副本的增加和减少,不能直接更改数量就什么都不管了,而引入消息队列的话,我会省心一些。
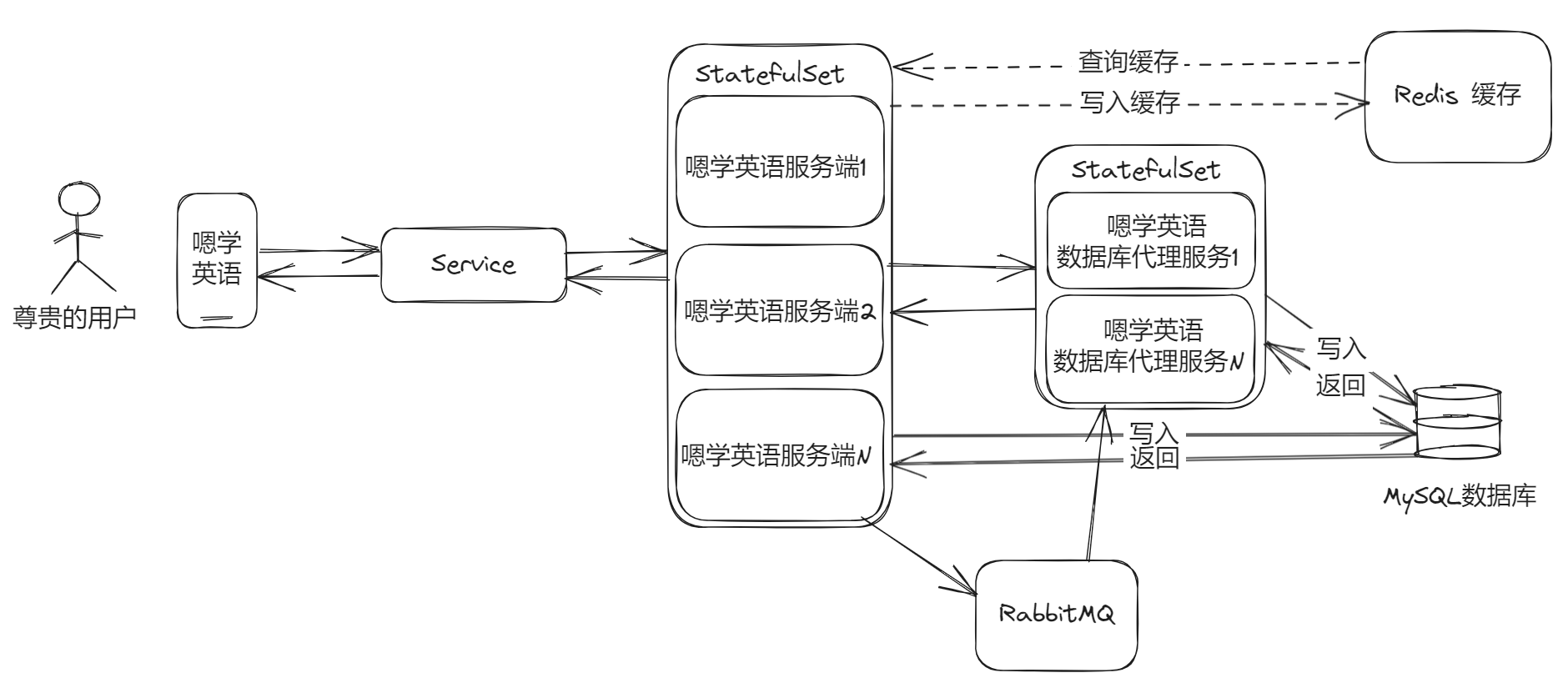
消息队列的引入,不仅异步写入降低了一些负载压力,同时也能极大的降低死锁和锁竞争出现的概率。出现这个问题,本质上还是太多的请求同时都来操作这一条数据导致的,我们让请求进入队列,就能避免啦!引入消息队列后,代理服务现在就成为了“消费节点”,我们依旧可以通过线程池或者增加副本的方式,来提升“消费能力”。
除了架构层面,我们在开发时,在代码层面也需要多多注意,应避免全表扫描对表中的所有行记录进行加锁。很多小伙伴开发时可能暂时不会考虑这么多,但是功能完成后,我还是建议看一看执行计划(EXPLAIN)。因为有时候光看 SQL 不一定看得出来,而且不同的数据量执行的 SQL,执行计划也可能差别很大。同时也要对 Slowest queries 进行监控,有剑不用和无剑可用那不是一回事儿。
最后
这就是我对嗯学英语核心业务的思考、设计和改进的一个过程了,当然也有很多应该做的东西也还没做,但实际上“黑天鹅”事件真出现了,也是很难顶得住的。后面继续开发迭代的过程中,我可能也会做出很多调整,等开发完了开源出来,可能也会跟本文所讲的有很大的偏差。
毕竟还有很多内容没考虑进来,比如中间件都挂了怎么办?我要怎么对每一个链路进行“观测”(以及错误追踪)?线上出了问题怎么告警(当然是咱们的老朋友 Prometheus 和 Grafana 啦)?怎么查询日志(ELK 太重了,每个 Pod 都打开看也麻烦)?依托于 K8S,我能以低成本去构建出满足这些的嗯学英语,从而更多时间能放在代码层面去思考。
最后感谢你能看到这里,有想法欢迎与我交流!